
Cette semaine j’ai voulu héberger un LLM sur ma machine qui est relativement puissante, afin d’éviter de redonner des sous à Anthropic. Suite à une vidéo sur DeepSeek 4 : DeepSeek V4 AI Beats Billion Dollar Systems…For Free, je me suis dit que j’allais tester ça !
Je pars de loin, car je n’ai jamais rien suivi des IA open-weight et je me suis toujours contenté de payer pour de gros modèles propriétaires comme Claude Opus / Chat GPT. Je ne m’étais jamais trop intéressé aux paramètres, à la quantization et au jargon du métier.
Open-weight signifie que les paramètres entraînés du modèle sont publiés publiquement, ce qui permet à n’importe qui de les télécharger et de faire tourner le modèle soi-même.
Je me renseigne un peu et finis par opter pour Ollama pour faire tourner les modèles sur ma machine. En une simple commande, on peut exécuter une intégration avec un modèle particulier. Il y en a un paquet ; je ne sais pas s’ils y sont tous, mais pour moi le choix est déjà immense.
Je cherche donc DeepSeek dans la liste et je trouve 2 versions : flash et pro. Je sélectionne la version flash, je la pull et quelques secondes après j’ai mon opencode de prêt à fonctionner ! Impressionnant. Seul hic : en retour d’un prompt on reçoit ce message :
Forbidden: this model requires a subscription, upgrade for access: https://ollama.com/upgrade
Ah ! C’était donc ça le tag cloud qu’il y avait sur le modèle. En fait, ce tag signifie que le modèle n’est pas hébergé en local et pointe vers les serveurs d’Ollama. Évidemment, cela nécessite une souscription à 20 € par mois. Sur le coup je n’ai pas compris le principe, mais on verra plus tard qu’il y a un besoin.
Ok, donc en fait pas moyen d’avoir DeepSeek 4 avec Ollama sans passer par une souscription. Je décide de prendre un autre modèle, il y en a plein après tout. J’ai cherché kimi-k2.6 et c’est encore un modèle cloud (EDIT: kimi n’est pas open-weight). Après quelques recherches, je me lance sur qwen3.6 qui fait du bruit en ce moment. 23 Go de téléchargement plus tard et je suis prêt à tester sur mon projet en cours.
Je lance un opencode sur un projet Go et je lui demande de faire le service de login. Il mouline 5 minutes, fait pas mal d’erreurs et se corrige lui-même, mais ce qui me surprend le plus c’est le nombre indécent de fichiers corrompus :
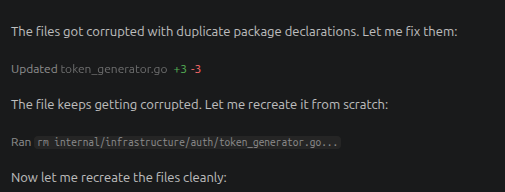
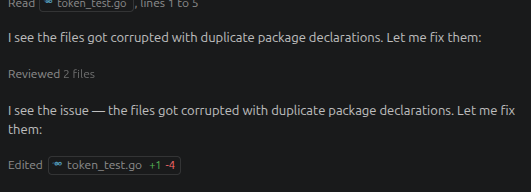
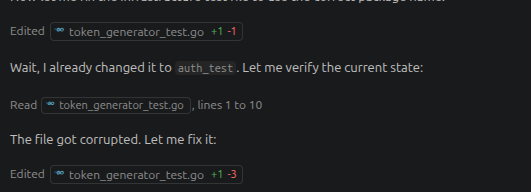

Il finit par corriger les problèmes, mais j’ai été très surpris. Un petit prompt à Claude pour demander ce qu’il se passe et il m’explique que c’est probablement parce que mon modèle ne tient pas entièrement en VRAM. Effectivement, un ollama ps me retourne ceci :
NAME ID SIZE PROCESSOR CONTEXT UNTIL qwen3.6:latest 07d35212591f 28 GB 18%/82% CPU/GPU 64000 4 minutes from now
Ma carte ne possède que 24 GB de VRAM, donc le modèle est partagé entre le GPU et le CPU, la RAM et la VRAM. Je décide donc d’essayer d’autres modèles pour voir si en prenant un plus léger j’aurais moins de corruption. J’ai donc essayé gemma4 et devstral-small-2 et j’obtiens des résultats mitigés. Au lieu de corruption, les prompts partent en boucle ou s’interrompent carrément en pleine réflexion. Je n’ai pas trouvé comment résoudre le problème ; il y a des variables à modifier mais ça devient très compliqué.
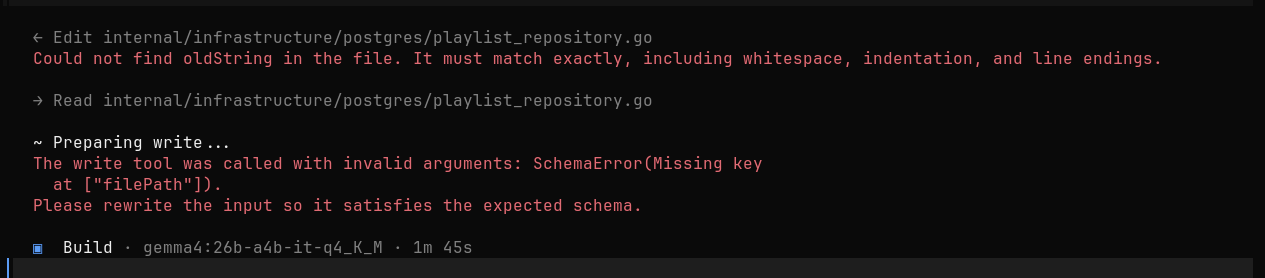
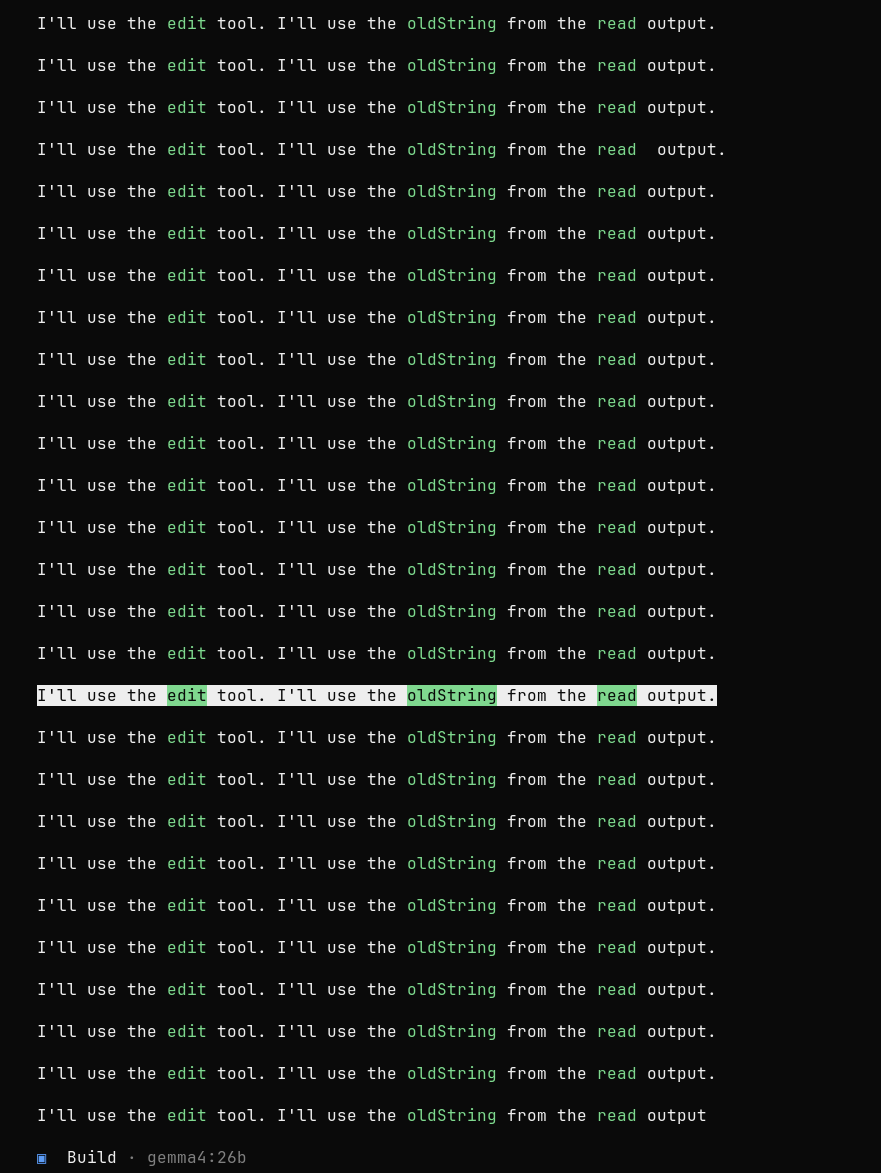
Je me dis que c’est peut-être encore que les modèles rentrent à peine en mémoire (23 GB / 24 GB) et qu’il n’y a pas assez de place pour le contexte, ou je ne sais quoi. C’est à partir de là que j’ai découvert la quantization. Un terme barbare qui signifie qu’on limite la précision des nombres à virgule afin de réduire la taille des modèles. Évidemment, moins de précision rend aussi le modèle moins intelligent. Voici un exemple de différentes quantizations pour un même modèle :
qwen3.6:latest qwen3.6:27b qwen3.6:35b qwen3.6:27b-coding-mxfp8 qwen3.6:27b-coding-nvfp4 qwen3.6:27b-coding-bf16 qwen3.6:27b-mlx-bf16 qwen3.6:27b-mxfp8 qwen3.6:27b-nvfp4 qwen3.6:27b-q4_K_M qwen3.6:27b-q8_0 qwen3.6:27b-bf16 qwen3.6:35b-a3b qwen3.6:35b-a3b-coding-mxfp8 qwen3.6:35b-a3b-coding-nvfp4 qwen3.6:35b-a3b-q4_K_M qwen3.6:35b-a3b-coding-bf16 qwen3.6:35b-a3b-nvfp4 qwen3.6:35b-a3b-q8_0 qwen3.6:35b-a3b-bf16 qwen3.6:35b-a3b-mlx-bf16 qwen3.6:35b-a3b-mxfp8
Bon courage pour comprendre quoi utiliser, sachant qu’à chaque fois c’est une vingtaine de giga à télécharger afin d’essayer. J’ai testé des NVFP4 en pensant que c’était bien vu que j’ai une NVIDIA, mais ça ne fonctionne que sur Mac 🤦♂️. La taille des modèles n’indique pas non plus combien de mémoire on a besoin. J’ai pris des modèles à 17 GB qui ne tenaient pas dans mes 24 GB. C’est encore un peu le far west je trouve, mais plus je m’y intéresse, plus je devine ce que je peux essayer.
J’ai donc passé plusieurs jours à faire quelques features sur mon projet (bien moins que si j’avais codé à la main, mais c’est le prix des expérimentations). C’est un projet multi-LLM, il y a des commits venant de chaque modèle testé.
Je tire 4 conclusions de ces expérimentations :
- Faire tourner un agent sur un GPU de 24 GB est bien utopique. Avec les progrès actuels je ne doute pas qu’on s’en rapproche ; je retesterai à l’occasion tous les 6 mois.
- Je comprends donc aussi qu’investir 20 € par mois pour un gros LLM propriétaire n’est pas cher payé pour l’avantage que ça apporte. Je ne doute pas que les prix vont grimper en flèche très rapidement. Pour un développeur, j’imagine que ça tournera autour de 200 € par mois afin d’avoir suffisamment de tokens pour travailler sans trop de cooldown.
- Je pense donc que les local LLM visent un tout autre marché : ajouter de l’IA à une application gratuitement (hors coût du matériel).
- Enfin, les modèles cloud de chez Ollama ont un intérêt pour utiliser d’énormes modèles open-weight qu’on ne pourrait pas héberger soi-même.
Je commence à comprendre pourquoi il y a une pénurie de RAM dans le monde…